Batch Geonews: TIGER 2013, ArcGIS for WordPress, RTK GPS for $2k, Yosemite Fires, and much more
Tue, 2013/09/03 – 10:18 — Satri
Catching up the August geonews, we’re now all up to date with this way too long entry.
On the open source front:
- The new open source GraphHopper Maps – High Performance and Customizable Routing in Java based on OpenStreetMap data (via OSM)
- Here’s Quantarctica, a free GIS package for Antarctica, the basic package is 7 gigs of free geodata and works with QGIS
- MapBox has an entry on the US Census Bureau released the 2013 version of TIGER
- There’s more of those, the first Open Source Geospatial Lab in Switzerland is established at SUPSI, Ohio’s First Open Source Geospatial lab will be established at KSU, and another one, First Australian Open Source Geospatial Laboratory at the University of Melbourne
- Frequent improvements, GeoTools 9.5 Released, GeoServer 2.3.5 Released, and Geopaparazzi 3.6.0 is out
- MapGuide Open Source is still alive and a major release planned for next year, meanwhile, Announcing: MapGuide Open Source 2.4.1 and 2.5.1
- Try open source software easily, OSGeo-Live 7.0 Released
On the Esri front:
- WordPress and Esri are both very popular, this gives us a WorldPress Plugin for ArcGIS Online: Spatial-Blogging for all Bloggers
- Esri released ArcGIS for State Government
- Here’s an open source boilerplate for ArcGIS API for Javascript apps
- From Esri Press, the second edition of book ‘The GIS 20: Essential Skills‘
- MS and Esri, Bing Maps Use in ArcGIS Has Changed
- Updates, ArcGIS API for JavaScript Version 3.6 Released and ArcPad 10.2 Released
Discussed over Slashdot:
- More free data, Using Zillow’s Creative Commons Neighborhood Boundary Data For the U.S.
- Microsoft acquires a part of Nokia, including access to Nokia mapping services
- Patents block innovation, How Patent Trolls Stalled a New Transit App
- Mapping unhappiness, Twitter-Based Study Figures Out Saddest Spots In New York City
- With MapBox behind, Open Source Mapping Software Shows Every Traffic Death On Earth, on a similar topic, Visualizing New York’s Road Accidents With the Interactive ‘Crashmapper’
- Old maps, Ostrich-Egg Globe Believed Oldest To Show New World
- More competition for driverless cars, Nissan Plans To Sell Self-Driving Cars By 2020
- Sharks with lasers? Great White Shark RFID/Satellite Tracking Shows Long Journeys, Many Beach Visits
In the miscellaneous category:
- Another insightful entry from Brian Timoney, with an example of how difficult it can be to simply get the latest US state boundaries
- Kickstarter to get a 4-cm accuracy real-time kinematic GPS for only 2,000$, named Piksi
- OGC standards and Advancing Toward Spatial Data Quality Assurance
- MapBox has been testing their upcoming quick access to satellite imagery ’MapBox Satellite Live’
- Another research indicating using GPS negatively impact our internal picture of the world
- MapQuest wants to stay relevant with their new spatially aware Data Manager API web service
- Here’s the YouSayCity, a 3D tool to discuss and document the future of individual cities
- Not directly geospatial, Discover the World’s Greatest Internet Cities
- While it’s a rather poor game, gamification of crowdsourcing geospatial data is here, this example of the Landspotting iPad app to crowdsource satellite imagery classification in a game, I preferred the Kort game to improve OpenStreetMap
- Wired shared an article on Google Map Maker, OpenStreetMap and the State of Crowdsourced World Mapping
- Nothing surprising, Apple too will leverage its users, iOS 7 Will Ask Users To Help Improve iOS Maps, Apple also acquired Embark to Further Improve Mass Transit Navigation
- In-the-house mobile devices, Are Mobile Users Really Mobile? Not So Much
- With Agile everywhere, it’s Agile somewhere, 17th AGILE Conference on Geographic Information Science
- Don’t know how many people there is an in area? Use the pickle consumption index
- Something we heard before, the geospatial identity crisis and the term ‘geomatics’
- We mentioned it in 2010 and here’s an updated about Gmap4: REST and WMS Map Viewer for Google Maps and GIS Data
- Another OGC entry, this time on big data and Big Processing of Geospatial Data
- A generic NYT article on Microsatellites: What Big Eyes They Have
- Drones again, Light-weight UAV-mounted laser scanning system announced
- Future unevenly distributed, Video Flashback 1987: Star Trek’s Shatner Tells You Where You Can Stick Your Maps
- Pretty interesting, geo doesn’t have to be that complex, James Fee shares GIS Is Complicated by Design
In the maps category:
- Yosemite fires entries: The Fire Last Time: Mapping Blazes Past, Present – and Future, 6 Months of Wildfires Burning North America, and Yosemite Fire’s Destruction Mapped in Beautiful, Frightening Color
- Another source for marine traffic, Visualize and Monitor Maritime Vessels, Real-time on Google Earth
- Map of Nobel prizes, A visual exploration of the Nobel Prize history
- An printed atlas, Atlas of the World Wide Web
- Maps of war, Targeting Sites of Attack in Syria
- Correlation is not causation, maps of Milk, the Drink of Conquerors
- Via Wired, don’t miss (really) this London’s Underground With This Mesmerizing Interactive 3-D Map
- On a similar topic, the Interactive Map of the Paris Metro
- A new version, the nice Submarine Cable Map 2013
















 I believe that the geospatial industry has lagged behind the general IT landscape, with concepts like “Big Data” and “Cloud Computing” taking longer to gain a solid foothold. Buzzwords aside, technology has changed a lot but much of the traditional GIS industry has not been aware of these changes. This will be a pivotal year, fueled in part by open source communities that think outside the box, solve real problems, and don’t need to work at the speed of a large proprietary monopoly.
I believe that the geospatial industry has lagged behind the general IT landscape, with concepts like “Big Data” and “Cloud Computing” taking longer to gain a solid foothold. Buzzwords aside, technology has changed a lot but much of the traditional GIS industry has not been aware of these changes. This will be a pivotal year, fueled in part by open source communities that think outside the box, solve real problems, and don’t need to work at the speed of a large proprietary monopoly.

 Ten years ago, when PostGIS was at 0.8 and the world was fresh and new, I was pretty convinced our industry was on the cusp of an open source revolution. When folks got a taste of the new, flexible, free tools for building systems they’d naturally discard their legacy proprietary software and swiftly move on to a more enlightened existence. I felt excitement, and wind in my hair.
Ten years ago, when PostGIS was at 0.8 and the world was fresh and new, I was pretty convinced our industry was on the cusp of an open source revolution. When folks got a taste of the new, flexible, free tools for building systems they’d naturally discard their legacy proprietary software and swiftly move on to a more enlightened existence. I felt excitement, and wind in my hair.














 Before we start playing with blocks, you should know the tools we’ll be using: Swift, SpriteKit and Xcode.
Before we start playing with blocks, you should know the tools we’ll be using: Swift, SpriteKit and Xcode. Or
Or When the new project window appears, choose Game from under the iOS > Application category and press Next.
When the new project window appears, choose Game from under the iOS > Application category and press Next. The next window beckons you to customize options for your project. Fill out the fields described in the table below:
The next window beckons you to customize options for your project. Fill out the fields described in the table below:

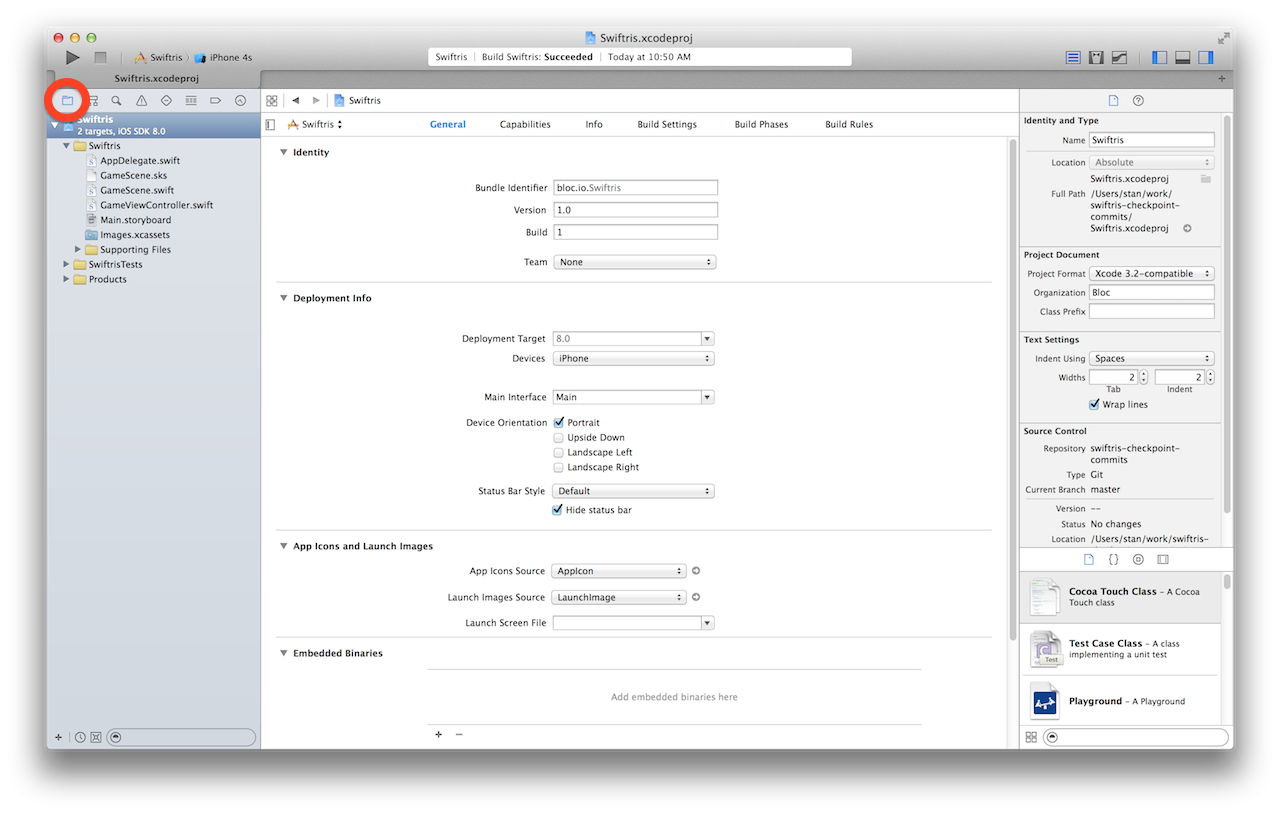 Right-click
Right-click  When asked to confirm, make sure to choose Move to trash:
When asked to confirm, make sure to choose Move to trash: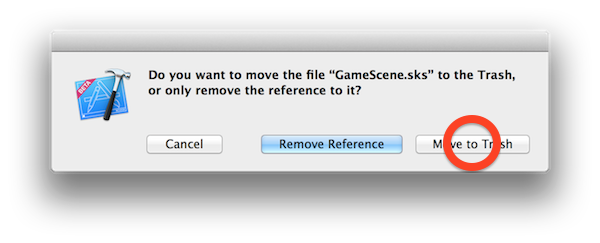 To get rid of the aimless space ship once and for all, click the
To get rid of the aimless space ship once and for all, click the 
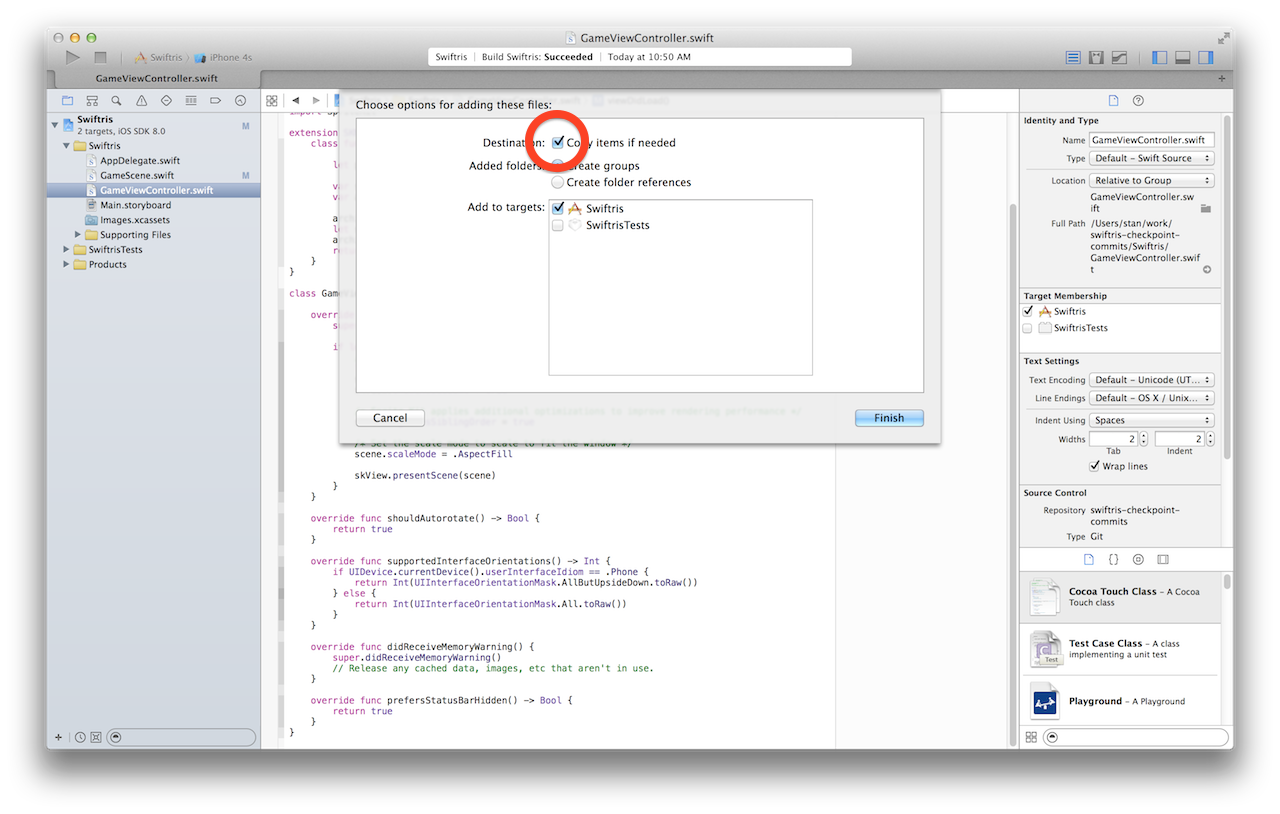 Make sure to check the Copy items if necessary option. This will place a copy of the directory and all of the sound files within it into your Swiftris project and directory. Click Finish. Repeat this task with the
Make sure to check the Copy items if necessary option. This will place a copy of the directory and all of the sound files within it into your Swiftris project and directory. Click Finish. Repeat this task with the

 PostGIS 2.0 will enable a new class of Heroku applications that leverage location data. Whether you are looking to
PostGIS 2.0 will enable a new class of Heroku applications that leverage location data. Whether you are looking to 

























