微信小程序终于开始公测了,这篇文章也终于可以发布了。
这篇文章可以说是微信小程序系列三部曲最后一篇。8 月份,小程序推出前,我写了《别开发 app 了》详细阐述了为什么创业应该放弃原生 app 开发,上个月,《为什么你觉得只开发微信号是不行的》从做生意的角度分析为什么应该把目光放在微信平台。今天,这篇文章可能是大家最期待和最失望的。
期待是因为这篇文章我将会分享我看到小程序生态里的机会,失望是,我无法手把手教你如何在这个新平台里挣钱,就像我无法告诉你如何快速赚钱人生第一个一百万。
更多地,我希望给大家带来一些思考,产品层面与思维层面的。
![博客]()
要了解小程序生态里会有哪些机会,我们需要先了解一些底层信息。
微信为什么要做小程序?
微信公众平台有 3 种公众号:订阅号、服务号、企业号,企业号用得比较少,我们暂时不去讨论。过去几年,订阅号的发展可以说超乎了所有人的想象力,以前没有人会觉得投资一个没有产品的订阅号是有价值的。
订阅号与服务号现状
让我们先来看看订阅号和服务号分别做得如何。
我们可以看到了「一条」这样的订阅号大户,也看到像「咪蒙」那样的让许多媒体人眼红的订阅号:
![屏幕快照 2016-10-30 下午4.20.59]()
也少不了像「同道大叔」这样的星座号,当然,还有个人色彩非常强烈的「博客」,比如「小道消息」:
![屏幕快照 2016-10-30 下午4.21.16]()
服务号层面,招商银行信用卡经常被提起,「朝夕日历」是一个体验层面做得非常优秀的日程管理服务号:
![屏幕快照 2016-10-30 下午4.20.28]()
在「助理来也」,你可以订购身边的各种服务,你也可以通过「我的印象笔记」把阅读的公众号文章存到印象笔记(中国版)里:
![屏幕快照 2016-10-30 下午4.21.51]()
订阅号与服务号的出现,让微信逐渐成为一个生态,用户无需离开微信,即可完成阅读、社交、获取生活服务等。
服务号无法解决高频使用的问题
按照微信的期待,订阅号本应为用户提供内容,但被玩出了各种营销和电商的花;服务号本应为用户提供各种服务,但真正做起来的服务号却少之又少,你可能听说过不少 VC 投资订阅号,但很少有 VC 投资服务号。
服务号发展得并不好。大多数服务号只是在做替代短信的推送服务和低频服务。
比如,被视作经典案例的招商银行信用卡公众号,用户的使用场景以收通知为主,它只不过替代了刷卡短信通知,其它功能很少被用到。
不妨想想我们为什么会下载一个产品的 app,而不用它服务号里一模一样的功能:
- 体验差,HTML 的体验比不上原生、流畅性差
- 层级多, App 一打开就是服务目录,服务号需要多进至少一层
- 对网络过于依赖,没有网络,服务号无法使用
对于低频使用的场景,即使体验差、层级多、每次都需要联网,用户是可以忍受的,比如查询信用卡额度,这种行为可能每个月只有一两次,即使网页的体验很差,但我们能忍受。
但对于高频使用场景,比如文档编辑,我们每天可能需要使用很多次,这时我们对体验、速度、稳定性显然有更高的要求,服务号和 HTML 并不能完美满足这些要求。
矛盾来了,微信希望第三方用服务号来为用户提供服务,但从功能层面,服务号却只解决了低频服务的需求,高频服务用户依然需要下载 app。
这时,微信需要提供另一种能力,来满足高频服务的需求。
微信想成为唯一的入口
为什么微信非要满足高频服务的需求?
因为商业是贪婪的,商业的最终目的是垄断。
8 亿活跃用户对微信来说是不够的,一天只占用用户 4 个小时对微信来说也是不够的,光提供信用卡消费通知对微信来说还是不够的。
微信想要更多,腾讯想要更多。当微信已经是超级入口,它想变成唯一的超级入口,它要占据你更多的时间和使用场景。它可能永远不会做一个 OS,但它希望成为「事实上」的 OS。
小程序是微信成为事实 OS 的必要补充。因为它的诞生是为了满足服务号没有满足好的高频应用场景。
所以,三管齐下,微信希望占据:
![屏幕快照 2016-10-30 下午4.26.26]()
- 更多用户时间
- 更多应用场景
- 更多服务入口
订阅号解决阅读需求,服务号满足低频服务需求,小程序定位在高频使用场景。
听起来很恐怖,但恐怕没有人能在短期内阻止微信成为事实 OS。
小程序是一个独立生态
把小程序理解为一个独立生态非常重要,这能让我们更容易看清楚小程序里存在的机会。
什么是生态?
我对软件生态的理解是这样的:
![屏幕快照 2016-10-30 下午4.27.13]()
- 一个大平台打造了这个生态
- 为所有开发者提供统一的入口
- 有统一的开发语言
- 对 UI、运营等方面有严格的规范
- 平台与开发者分成、共赢
对比苹果与微信
按照前面的定义,我们可以很容易得出,苹果 App Store 的生态结构:
![屏幕快照 2016-10-30 下午4.27.22]()
- 苹果是大平台
- 统一入口是 App Store
- 统一用 Swift 或 Obj-C 语言进行开发
- 苹果对 UI、运营等方面有严格的规范
- 苹果与开发者分成收入
我们再来看看微信小程序的生态:
![屏幕快照 2016-10-30 下午4.27.32]()
- 微信是大平台
- 统一入口是微信 app
- 统一用小程序语言进行开发
- 微信小程序提供了详细的 UI、运营等规范
- 目前还未与开发者分成收入,但以后有这个可能性
相比起服务号,微信在小程序的生态建设上花了更多功夫,比如之前并没有 UI 规范、以前并没有独立语言,这些都让小程序慢慢变成一个独立生态。
如何用生态思维发现新机会?
任何一个新生态的出现,都会带来以下机会:
- 新的应用场景,甚至新的用户
- 原来在别的生态存在的应用,会以新的形态重新出现
- 微信开发,将会是独立岗位,就像 iOS 开发
对于第 3 点,我是深信不疑的,所以有可能学院在今年7月就推出了「微信公众号与小程序开发」课程,周期为 2 个月,认真培养和我们一样有前瞻性的人。
![屏幕快照 2016-10-30 下午4.28.53]()
你可以回想 08 年 App Store 刚推出时,赚到第一波红利的,是不是抓住这些机会。
当然,认识「红利」这个词的人已经比 08 年多多了。
正确理解微信小程序
自从张小龙 2016 年初提出做「应用号」,外界对应用号的猜测和期待从来没有停止过。大多数人和媒体认为,小程序将会为营销带来新机会。
我觉得很多媒体把小程序的机会方向带偏了,小程序的营销能力其实是很差的,他们或许没有细看小程序的开发文档,甚至没有参与过小程序开发或与开发者进行深入交流,就,嗯,有点乱写。
以下 10 点对小程序的理解来自我对小程序文档的解读和实际开发,期间,我也与微信的工作人员有一些交流。
小程序是微信接下来的重点产品
甚至是最高优先级的产品之一,因为这是微信要成为真正的 OS 的路径。前面已经论述过这一点。
这意味着,开发者可以完全放心把精力和资源放到小程序上。
无关注,无心理压力
和服务号、订阅号不一样,小程序是没有关注功能的。这意味着,对用户来说,心理成本更小,用户通过搜索进入小程序,马上就可以使用,不像服务号还需要先关注。
但对开发者来说,这显然不是好事。这意味着:
- 你无法群发消息,因为你根本没有关注者
- 你可能需要自行建立用户系统,但转化率是个问题
所以,小程序在一定程度上,提高了产品运营能力的要求。
不是 HTML5,也不是 Hybrid
我们经常在朋友圈看到的非常炫酷还带背景音乐的 H5 页面,将不会在小程序里出现。
微信小程序开发使用改自 Javascript, CSS, XML 的语言,同时提供了各种自有的组件和 API,这让小程序变得独立:
- 它不兼容 HTML,网页代码在小程序里无法使用
- 开发之前,开发者需要熟悉小程序开发语言,按照微信的命名方法,说不定会被称为 WeLang。
不兼容 HTML,不仅意味着你不能在页面里使用 HTML 标记,也意味着你不能嵌入 HTML 网页:要么不嵌入,要么用 WeLang 重写。
没有外链
不兼容 HTML 还意味着,你无法在小程序里放置外链。HTML 里的 <a> 标记是被禁止的。
这很大程度上限制了营销,服务号里,我们好歹还能在文章里插入链接,而目前版本的小程序,是不能插入外链的,哪怕是放置二维码,直接在页面上长按,也没有「识别二维码」选项(当前版本)。
限制得很狠,不是么?还有更狠的。
无法分享到朋友圈
是的,那种鼓吹小程序能带来营销大机会的媒体要被打脸了,至少被目前版本的小程序打脸了。
当前版本的小程序是不支持分享到朋友圈的,你可以将小程序的任何页面分享给通信录的个人或群,但无法分享到朋友圈,这意味着你不会在朋友圈看到小程序刷屏,刷屏的,还是原来那些东西。
从经验上来看,微信会尽一切努力维护朋友圈秩序。以后小程序能不能分享到朋友圈我不知道,但至少一开始不打开这个口对微信来说是好事,一旦打开,就很难收回来了。
用微信语言开发的原生程序
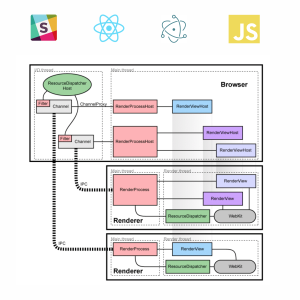
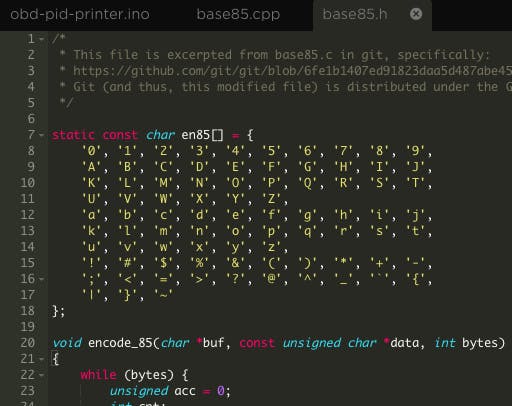
前面已经提到过,微信小程序不是用 HTML 开发的,也不兼容 HTML 标记,它是一套自有的语言(暂且叫 WeLang),使用 WeLang 开发出来的页面,其体验是与原生 app 接近的,因为除了数据,定义页面的样式、数据结构、逻辑等文件已经提前下载,不像网页那样需要实时加载,而且,因为页面可以调用小程序提供的组件,这些组件早已内置在微信客户端,它们的体验其实就是「原生」的。
一个微信页面包含 4 个文件:
- WXML:页面结构
- JS:页面逻辑
- WXSS:页面样式
- JSON:页面配置
![屏幕快照 2016-10-30 下午4.33.37]()
注:这 4 个文件非层级结构。
其中 JSON 文件不是必须的,这 4 个文件在用户下载小程序时就已经下载到本地 — 就像原生 app 那样,小程序只需要连接 API 获取指定数据。
这样的体验,是非常流畅,非常原生的。
前端开发成本极低
前端开发其中一个最大的成本是兼容性适配,不管是做网页的前端需要适配各种浏览器,还是做 Android 客户端开发,需要在各种尺寸、性能不同的设备中反复调试。
对于创业公司来说,这些成本的支出是不划算的,因为创业公司需要快速将产品推出市场,兼容性问题往往为快速迭代带来障碍。
开发微信小程序,对于前端工程师来说,成本是相对较低的,因为微信已经解决了兼容性问题,前端工程师只需要学习 WeLang,然后按照规范去开发,兼容性问题,交给微信。
一次开发,多平台通用。
离线使用与 Websocket 的想象力
微信小程序支持离线使用,也支持后台运行,这为小工具带来想象力。
比如,像万年历、Todolist、番茄闹钟这样的工具,会大量出现。我更期待的是,微信将来提供一种会话与小程序之间直接通信的能力。
![屏幕快照 2016-10-30 下午4.34.40]()
小程序很多 API 与服务号类似,但其中的 Websocket API 是新增的。很多拿到内测的朋友都跟我说,这个新的 API 可以带来巨大的想象力,比如,你可以在小程序里打造一个「你画我猜」的游戏。
但我更期待的是,这个实时通信 API 能否会为垂直社交带来新可能性。这一点,后面会详细讨论到。
没有游戏,没有直播
是的,「你画我猜」其实是无法出现在小程序平台的。
目前版本小程序文档里明确写明,游戏类、直播类、小程序导航,小程序链接互推,小程序排行榜等都不能提交。
有审核机制
前面提到了「提交」这个词。和订阅号、服务号不一样,你发文章不需要通过微信审核,你改按钮功能也不需要,但小程序的每个版本更新,都必须通过微信审核 — 就像 App Store 那样。
![q]()
对用户来说,这是好事,意味着大部分通过审核的服务都是质量过关的,坏消息是,对于只把目光放在营销层面的人,这里又是另一个限制。
有哪些机会?
小程序之所以「小」,除了因为安装包不超过 1024 KB,用户即搜即用之外,还因为它定义了新的应用场景 — 直达服务的场景。
![屏幕快照 2016-10-30 下午4.50.29]()
相信很多人都看到张小龙对微信小程序的定义:即用即走、触手可及。从他的原话以及我们开发小程序的过程,我对这句话的理解是,微信期待小程序为用户提供更快速的直达服务,比如用户在搜索框搜索「北京到上海的机票」,小程序应该立刻转到机票列表页,而不是小程序的介绍或繁琐的注册过程。
实际上,用户不仅可以搜索小程序的名称和描述,还能搜索其最多 5 个功能性页面,这意味着,微信特别强调搜索直达的使用场景。
结合小程序提供的功能和新的应用场景,我们来谈谈小程序里有哪些机会。
从其它生态复制过来
复制比创新容易,而新生态对应用多样性也有强烈的需求,所以你很快会看到,会有大量的人从 App Store 「复制」应用到小程序。
![屏幕快照 2016-10-30 下午4.52.54]()
第一波被复制过来的,很有可能是各种开发门槛相对较低的查询类产品,查电话归属地、查快递、查星座、查空气质量等。
复制的时候,需要注意的是,微信对小程序的用户场景定义是不一样的,照搬可能不是最好的思路,需要做适当的要整。
别硬拼渠道
前面提到的查询类产品,是我拍脑袋想到的。同样,在这个行业稍有经验的人,也能拍脑袋想到。
这意味着,和你一样,想着从 App Store 搬运应用到小程序的人非常多。如果你只是一个独立开发者或小创业公司,不妨搁置这个想法,因为这类产品最终考验的渠道能力,不是产品设计能力。
电商
能补足腾讯缺口的产品可能都会被鼓励,电商就是最有想象力的领域之一。
电商的最大入口在阿里手上,虽然腾讯手上有京东、微店等电商平台,但体量总和与淘宝、阿里巴巴相比还是有很大的差距。
微信希望占领用户所有的应用场景和服务入口,电商当然是不例外的,而恰好,电商也是腾讯急迫需要的,为什么购物还要打开淘宝?
从这个角度来看,电商方向的小程序会大量出现,腾讯一定会从政策上有所鼓励。这么看来,淘宝与微信的互相屏蔽,可能会为小程序里的电商生态奠定基础。
垂直社交
我们的微信通信录是杂乱的,里面有家人、同事、同学,甚至还有发生过一次性关系的人。
订阅号们,一直尝试建立用户社群,但不管是用独立 app,还是用微信群,转化率都奇差无比。
这两个需求,以及 Websocket API,让小程序里的垂直社交成为可能。
![photodune-5787803-social-network-l-1940x1455]()
比如一个关注孕妇的订阅号,它可以利用小程序构建一个孕妇社区,孕妇们无需离开微信,就可以在社区里与她人沟通和购物。
比如,你还可以在小程序里复制一个 Tinder,让用户在里面统一管理他们的一次性关系,从技术接口和需求上,它都有出现的理由。
很多人期待微信开放关系链,我觉得它永远不会对外部产品开放关系链,但我认为,微信允许,也需要基于微信平台的垂直社交。
2B 产品与工具
毫无疑问,2B 类产品和工具将是小程序的热门领域,尤其是高频使用的工具类产品。
想象这样一个场景,你们公司内部沟通用钉钉,但无论如何,你与外部客户沟通时,还得使用微信。但微信与钉钉之间是没有数据同步的,这为内外沟通带来了不便利,你需要手动复制微信里的沟通内容粘贴到钉钉里。
又设想这样一个场景,你需要写一份与团队内部共享的文档,这份文档每天可能会更新好几次,以前的做法是在电脑上修改完发到公司群里。试想一下,为什么你不能在一个叫「团队网盘」的小程序(纯属虚构)里更新,团队成员只需要打开小程序,就能获取最新版本?
![]()
既然微信已经成为我们最常用的沟通工具,为什么不能把工作场景也搬进来?以前不可以,因为以前微信里没有沟通的屏障,所有沟通都混在一起,并不适合办公,因此他们推出了企业微信。
而现在,小程序可以成为这道「屏障」,办公的沟通,可以在小程序里进行,日常与外部的沟通,依然通过会话。如果某一天,微信提供了「会话 – 小程序」的通信能力,办公场景的流畅度会更上一层楼。
营销需要新思路
因为微信小程序对营销的限制:
- 没有关注功能
- 不能群发消息
- 不能内嵌网页和外链
- 不能分享到朋友圈
小程序的运营需要新的思路,最好的营销当然是提供用户最需要的服务,让用户口碑传播。除此之外,肯定还会有新的营销思路产生,我不知道会有哪些新思路,但我相信中国人的「聪明才智」,尤其是玩流量的高手们会想到新办法,不过,我也相信,微信会一如既往地限制过度营销。
内容型产品其实不适合做小程序
纯粹的展示型内容产品,其实不适合做小程序。我指的是纯粹的媒体。
媒体需要什么?公众注意力。
小程序没有关注、不能群发、不能分享到朋友圈,这意味着用户要找到这个媒体,只能通过搜索或二维码。显然这不是媒体的玩法,媒体的玩法是搞个大新闻,让所有人在朋友圈里转发,然后持续搞大新闻。
所以,订阅号依然是最适合媒体的公众号,但如果媒体公司有开发能力,可以同时做订阅号和基于小程序的社区,想方设法把订阅者转化到社区里。
其它机会同样需要变换场景思维
机会肯定不限于我说的这些,但无论在小程序里做什么类型的产品和服务,变化场景思维是很重要的,这要求我们在设计产品时,应该优先考虑用户如何迅速获得服务,而不是我们如何首先获得用户。
这听起来很简单,但做产品时,往往很难做取舍。
还是那句老话,创业先做微信号
微信已经是中国最大的互联网入口,小程序的推出,将让它占领更多用户场景和用户时间,从做生意的角度来考虑,用户在哪里、用户更多时间花在哪里,就应该在哪里构建入口。
相比起开发原生 App,开发微信公众号的优势我已经在《别开发 app 了》详细阐述,实际上,我身边已经越来越创业者选择不开发 app 了。
很多人担心两个问题:
- 苹果是否允许小程序的存在
- 被微信封杀了怎么办
第 1 个问题显然不用担心,两个大公司之间,没有什么是不可以谈判的。利益最大化是共同的追求。
对于第 2 点,我的理解是,微信的规则越来越清晰,哪些事能做哪些不能做,规则里都写明,但如果我们做了一个与腾讯利益有严重冲突的产品,可能还是会被封杀,毕竟腾讯是商业公司,不是公益组织。
另一方面,有时封杀我们的可能并不是腾讯。这一点,就不多说了。
当然,凡是留一手还是需要的,如果我们开发的是微信小程序,后端 API 其实和提供给 iOS 和 Android 的 API 是类似,任何时候,数据同时有一份握在自己手里是很重要的,那些承诺永不关闭终生免费的网盘不都关闭了么?这样也比较方便当你有巨量用户时,从微信移植到别的平台。
总之,红利是有的,但每个人都已经意识到了,除了快之外,别忘了把思维切换到「直达服务」的场景上。






















































































































 This is probably the most versatile, easy and resourceful data set in pattern recognition literature. Nothing could be simpler than iris data set to learn classification techniques. If you are totally new to data science, this is your start line. The data has only 150 rows & 4 columns.
This is probably the most versatile, easy and resourceful data set in pattern recognition literature. Nothing could be simpler than iris data set to learn classification techniques. If you are totally new to data science, this is your start line. The data has only 150 rows & 4 columns. This is another most quoted data set in global data science community. With several tutorials and help guides, this project should give you enough kick to pursue data science deeper. With healthy mix of variables comprising categories, numbers, text, this data set has enough scope to support crazy ideas! This is a classification problem. The data has 891 rows & 12 columns.
This is another most quoted data set in global data science community. With several tutorials and help guides, this project should give you enough kick to pursue data science deeper. With healthy mix of variables comprising categories, numbers, text, this data set has enough scope to support crazy ideas! This is a classification problem. The data has 891 rows & 12 columns. Among all industries, insurance domain has the largest use of analytics & data science methods. This data set would provide you enough taste of working on data sets from insurance companies, what challenges are faced, what strategies are used, which variables influence the outcome etc. This is a classification problem. The data has 615 rows and 13 columns.
Among all industries, insurance domain has the largest use of analytics & data science methods. This data set would provide you enough taste of working on data sets from insurance companies, what challenges are faced, what strategies are used, which variables influence the outcome etc. This is a classification problem. The data has 615 rows and 13 columns. Retail is another industry which extensively uses analytics to optimize business processes. Tasks like product placement, inventory management, customized offers, product bundling etc are being smartly handled using data science techniques. As the name suggests, this data comprises of transaction record of a sales store. This is a regression problem. The data has 8523 rows of 12 variables.
Retail is another industry which extensively uses analytics to optimize business processes. Tasks like product placement, inventory management, customized offers, product bundling etc are being smartly handled using data science techniques. As the name suggests, this data comprises of transaction record of a sales store. This is a regression problem. The data has 8523 rows of 12 variables. This is another popular data set used in pattern recognition literature. The data set comes from real estate industry in Boston (US). This is a regression problem. The data has 506 rows and 14 columns. Thus, it’s a fairly small data set where you can attempt any technique without worrying about your laptop’s memory issue.
This is another popular data set used in pattern recognition literature. The data set comes from real estate industry in Boston (US). This is a regression problem. The data has 506 rows and 14 columns. Thus, it’s a fairly small data set where you can attempt any technique without worrying about your laptop’s memory issue. This data set is collected from recordings of 30 human subjects captured via smartphones enabled with embedded inertial sensors. Many machine learning courses use this data for students practice. It’s your turn now. This is a multi-classification problem. The data set has 10299 rows and 561 columns.
This data set is collected from recordings of 30 human subjects captured via smartphones enabled with embedded inertial sensors. Many machine learning courses use this data for students practice. It’s your turn now. This is a multi-classification problem. The data set has 10299 rows and 561 columns. This data set comprises of sales transactions captured at a retail store. It’s a classic data set to explore your feature engineering skills and day to day understanding from your shopping experience. It’s a regression problem. The data set has 550069 rows and 12 columns.
This data set comprises of sales transactions captured at a retail store. It’s a classic data set to explore your feature engineering skills and day to day understanding from your shopping experience. It’s a regression problem. The data set has 550069 rows and 12 columns. This data set is originally from siam competition 2007. The data set comprises of aviation safety reports describing problem(s) which occurred in certain flights. It is a multi-classification, high dimensional problem. It has 21519 rows and 30438 columns.
This data set is originally from siam competition 2007. The data set comprises of aviation safety reports describing problem(s) which occurred in certain flights. It is a multi-classification, high dimensional problem. It has 21519 rows and 30438 columns. This data set comes from a bike sharing service in US. This data set requires you to exercise your pro data munging skills. The data set is provided quarter wise from 2010 (Q4) onwards. Each file has 7 columns. It is a classification problem.
This data set comes from a bike sharing service in US. This data set requires you to exercise your pro data munging skills. The data set is provided quarter wise from 2010 (Q4) onwards. Each file has 7 columns. It is a classification problem. Didn’t you know analytics can be used in entertainment industry also? Do it yourself now. This data set puts forward a regression task. It consists of 515345 observations and 90 variables. However, this is just a tiny subset of
Didn’t you know analytics can be used in entertainment industry also? Do it yourself now. This data set puts forward a regression task. It consists of 515345 observations and 90 variables. However, this is just a tiny subset of  It’s an imbalanced classification and a classic machine learning problem. You know, machine learning is being extensively used to solve imbalanced problems such as cancer detection, fraud detection etc. It’s time to get your hand dirty. The data set has 48842 rows and 14 columns. For guidance, you can check my
It’s an imbalanced classification and a classic machine learning problem. You know, machine learning is being extensively used to solve imbalanced problems such as cancer detection, fraud detection etc. It’s time to get your hand dirty. The data set has 48842 rows and 14 columns. For guidance, you can check my  This data set allows you to build a recommendation engine. Have you created one before? It’s one of the most popular & quoted data set in data science industry. It is available in
This data set allows you to build a recommendation engine. Have you created one before? It’s one of the most popular & quoted data set in data science industry. It is available in  This data set allows you to study, analyze and recognize elements in the images. That’s exactly how your camera detects your face, using image recognition! It’s your turn to build and test that technique. It’s an digit recognition problem. This data set has 7000 images of 28 X 28 size, sizing 31MB.
This data set allows you to study, analyze and recognize elements in the images. That’s exactly how your camera detects your face, using image recognition! It’s your turn to build and test that technique. It’s an digit recognition problem. This data set has 7000 images of 28 X 28 size, sizing 31MB. This data set is a part of round 8 of The Yelp Dataset Challenge. It comprises of nearly 200,000 images, provided in 3 json files of ~2GB. These images provide information about local businesses in 10 cities across 4 countries. You are required to find insights from data using cultural trends, seasonal trends, infer categories, text mining, social graph mining etc.
This data set is a part of round 8 of The Yelp Dataset Challenge. It comprises of nearly 200,000 images, provided in 3 json files of ~2GB. These images provide information about local businesses in 10 cities across 4 countries. You are required to find insights from data using cultural trends, seasonal trends, infer categories, text mining, social graph mining etc. ImageNet offers variety of problems which encompasses object detection, localization, classification and screen parsing. All the images are freely available. You can search for any type of image and build your project around it. As of now, this image engine has 14,197,122 images of multiple shapes sizing up to 140GB.
ImageNet offers variety of problems which encompasses object detection, localization, classification and screen parsing. All the images are freely available. You can search for any type of image and build your project around it. As of now, this image engine has 14,197,122 images of multiple shapes sizing up to 140GB. How could I miss KDD Cup? Originally, KDD brought the taste of data mining competition to the world. Don’t you want to see what data set they used to offer? I assure you, it’ll be an enriching experience. This data poses a classification problem. It has 4M rows and 48 columns in a ~1.2GB file.
How could I miss KDD Cup? Originally, KDD brought the taste of data mining competition to the world. Don’t you want to see what data set they used to offer? I assure you, it’ll be an enriching experience. This data poses a classification problem. It has 4M rows and 48 columns in a ~1.2GB file. The ability of handle large data sets is expected of every data scientist these days. Companies no longer prefer to work on samples, they use full data. This data set would provide you much needed hands on experience of handling large data sets on your local machines. The problem is easy, but data management is the key! This data set has 6M observations. It’s a multi-classification problem.
The ability of handle large data sets is expected of every data scientist these days. Companies no longer prefer to work on samples, they use full data. This data set would provide you much needed hands on experience of handling large data sets on your local machines. The problem is easy, but data management is the key! This data set has 6M observations. It’s a multi-classification problem.